21 dec 2021
|
Maatschappij
De vastgoedwereld sneller en betrouwbaarder met AI, hoe dan?
Journalist: Féline van der Linde
Binnen het vastgoed wordt er steeds meer gebruik gemaakt van slimme AI algoritmes en modellen om hen te helpen met het maken van beslissingen. Zo kunnen modellen helpen om de waarde van een huis te bepalen en kunnen ze vastgoedontwikkelaars helpen om de meest geschikte woningen te vinden voor hun project. Kunnen ze op dat stuk grond bijvoorbeeld beter een rijwoning of een twee-onder-een-kap woning bouwen? Een paar Data Science bedrijven in Nederland houden zich met deze vragen bezig. Toch is het voor veel mensen een raadsel hoe deze modellen precies werken en of deze wel te vertrouwen zijn.
“Als voorbeeld nemen we de Automated Valuation Model (AVM), voor het bepalen van de waarde van een woning”, vertelt Marlies Buijs, Data Scientist bij Veneficus Real Estate. “Dit model geef je een aantal kenmerken van een woning mee, zoals de grootte, de voorzieningen rond de woning en de demografie van de buurt. Het model geeft je dan een verwachte waardering van de woning terug. Om dit nauwkeurig te kunnen doen, heeft het model data nodig. Deze data bevat dus kenmerken van de woning en de bijbehorende waarde ervan. Het AVM model gebruikt data over vastgoedprojecten en bestaande bouw van de afgelopen jaren. Deze worden aangevuld met data van bijvoorbeeld het CBS over de demografie, WOZ waardes, inkomens, werkgelegenheid, maar ook de nabijheid van allerlei voorzieningen (denk aan winkels, horeca, groen) en bereikbaarheid, geluidsoverlast, et cetera.”
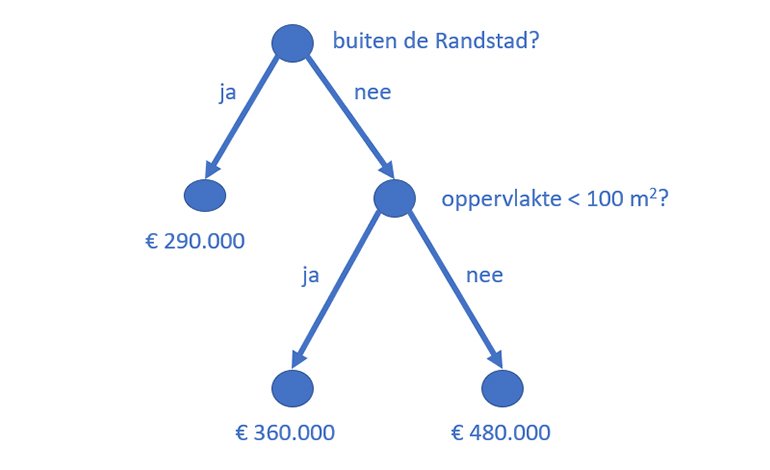
Er zijn talloze soorten modellen te gebruiken tegenwoordig, elk met zijn eigen voor- en nadelen. Met een XGBoost Regression model voorspel je huurprijzen aan de hand van geavanceerde beslisbomen. “Met behulp van de hierboven beschreven dataset is de beslisboom in elkaar gezet, dit wordt ook wel ‘trainen’ genoemd. Hiernaast is een voorbeeld te zien van een (zeer eenvoudige) beslisboom. Om de geschatte V.O.N (vrij op naam) prijs te weten, beantwoord je de vragen van boven naar beneden, en kom je uiteindelijk tot een waardering. Bij een XGBoost regressor worden meerdere beslisbomen op een geavanceerde manier gecombineerd, waardoor we een nog betrouwbaardere waardering krijgen. Elke beslisboom gebruikt net wat andere data en gebruikt een andere subset aan variabelen. De waardering van een woning is dan een combinatie van de waardering van de afzonderlijke beslisbomen”. Het idee achter het model is op zichzelf dus niet erg complex, maar door de enorme omvang ervan (XGBoost kan duizenden beslisbomen bevatten) wordt het voor mensen al snel niet meer inzichtelijk.
“Verder weten we dat data over bestaande bouw ook zou kunnen helpen bij het bepalen van VON prijzen van nieuwbouwwoningen. Toch zijn de eigenschappen van bestaande bouw en nieuwbouw te verschillend om deze data gewoon samen te voegen. Daarom wordt naast XGBoost Regression ook Transfer Learning gebruikt. Deze methode zorgt ervoor dat extra informatie uit bestaande bouw toch aan het AVM model kan worden toegevoegd, zonder dat het zorgt voor zogenoemde ‘ruis’ in de informatie die we uit de nieuwbouwwoningen halen.”
XGBoost wordt gezien als een zogenaamd Black Box model: je stopt er iets in en er rolt wat uit, zonder dat je precies weet waarom. Om toch inzicht te krijgen in de effecten van de afzonderlijke variabelen op de waardering van de woning worden SHAP (SHapley Additive exPlanation) waarden gebruikt. Dit is een techniek die we over het model heen leggen, om zo per waardering te zien hoe deze tot stand komt. We willen namelijk dat het inzichtelijk is welke variabelen invloed hebben op de voorspelde VON-prijs. Zo is het bijvoorbeeld mogelijk om te zien dat de supermarkt om de hoek ervoor zorgt dat de woningen ongeveer 50 euro per vierkante meter meer waard is.
Alhoewel AI steeds vaker wordt gebruikt, zijn niet alle modellen even betrouwbaar, besluit Buijs. “Voordat u de waarderingen van een model zomaar overneemt, is het zaak om zich een aantal dingen af te vragen. Ten eerste, hoeveel data is er gebruikt voor het model en waar komt deze data vandaan? Pas als er hoge kwaliteit data gebruikt wordt, kan er een hoge kwaliteit waardering uit het model komen. Ten tweede is het belangrijk te vragen naar een algehele performance van het model. Hoe goed waardeert hij de prijzen van woningen waarvan we de prijzen al weten? Zit hij hier gemiddeld vijf procent naast? Of misschien wel tien procent? Ga na welke foutmarge je acceptabel vindt. Ten slotte is het belangrijk te weten welke variabelen worden meegenomen in het model. Wanneer je bijvoorbeeld de waarde van een woning vlakbij een snelweg wilt bepalen, terwijl informatie over die snelweg niet in het model verwerkt zit, kunt je je afvragen of de waardering van het model wel klopt.”
Gesponsord










Gesponsord

© Copyright 2025 - Contentway. All rights reserved.
Webdesign & Development by Pola | Digital Agency Hamburg